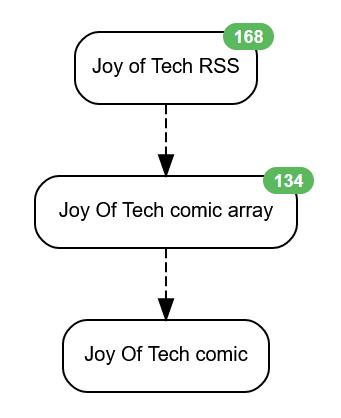
Huginn - RSS-Website-image-feed
Huginn can read RSS feeds & process the contents so that the important parts can be extracted, links followed & a new RSS feed created that delivers what I want, up front, with an option to follow through to the original website if that's attractive to me.
I'm going to use the Joy Of Tech web comic as an example, but some feeds need slightly different handling. One of the things that I struggled with was working out exactly how to spell out what parts of the inputs was needed in order to get to what I wanted, so this might help...
Let's start with the JoT RSS feed itself. You could open it in a web browser window & you'll see something like this:
<channel>
<title>Joy of Tech (RSS Feed)</title>
<atom:link href="http://www.geekculture.com/joyoftech/jotblog/" rel="self" type="application/rss+xml"/>
<link>http://joyoftech.com/joyoftech/</link>
<description/>
<lastBuildDate>Thur, 03 Feb 2022 00:00:39 +0000</lastBuildDate>
<language>en-US</language>
<sy:updatePeriod>daily</sy:updatePeriod>
<sy:updateFrequency>1</sy:updateFrequency>
<generator>https://wordpress.org/?v=4.8.14</generator>
<item>
<title>Training Videos VS Reality!</title>
<link>
https://www.geekculture.com/joyoftech/joyarchives/2871.html
</link>
<pubDate>Thur, 03 February 2022 00:00:39 +0000</pubDate>
<dc:creator>Snaggy</dc:creator>
<created>2022-01-31T00:00:32Z</created>
<summary type="text/plain">Be a part of the team!</summary>
<author>
<name/>
<email>snaggy@geekculture.com (Snaggy) </email>
</author>
<dc:subject>Comics</dc:subject>
<content type="text/html" mode="escaped" xml:lang="en" xml:base="http://www.geekculture.com/joyoftech/jotblog/">
<p><a href="https://www.geekculture.com/joyoftech/joyarchives/2871.html"><img src="http://www.geekculture.com/joyoftech/joyimages/2871joy300thumb.gif" alt="JoT thumb" width="300" height="300" border="0"></a><br><br>Be a part of the team!</p><p>https://www.geekculture.com/joyoftech/joyarchives/2871.html</p>
</content>
</item>Read the RSS
First thing is to convert that RSS feed into a set of data within Huginn. Let's read it using the website agent... Add an agent & then type "website" into the combobox:
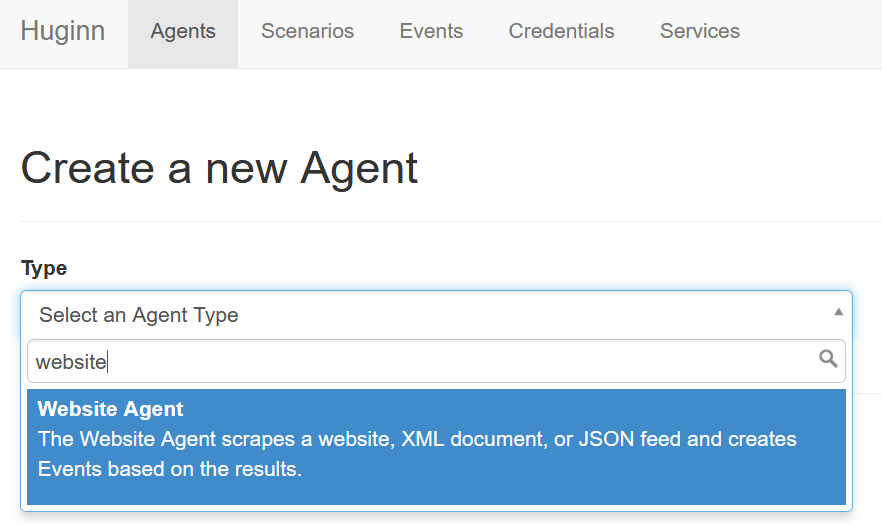
You'll want to set the schedule box to something suitable (I went for 12h, but pick an interval that works for you).
Huginn will then let you edit the agent either in a "friendly" interface, or the "raw" json. I'll show you the json, but you can toggle that into the "friendly" version if you want.
{
"url": "http://www.geekculture.com/joyoftech/jotblog/atom.xml",
"mode": "on_change",
"type": "xml",
"expected_update_period_in_days": "10",
"extract": {
"title": {
"css": "item title",
"value": ".//text()"
},
"url": {
"css": "item link",
"value": ".//text()"
}
}
}The extract section tells Huginn to read the xml of the RSS feed & to create an entry for each <item>: in which the content of <item>'s <title> is assigned to the "title" variable & the content of <link> is assigned to the "url" variable. Which is great, but having a variable that has the title of each comic & the link to that comic's web page is not that much use as it stands.
We want to see the comic in NewsBlur, but want to get to it as quickly as possible in our RSS reader, so the next step is to follow that webpage url (which was in the RSS feed as <link>) & to find the comic (graphic) within it.
So, we need to scrape a web page (for each comic). The one that is defined in the "url" part of the data that we just extracted.
First off we need another website agent (you know how to create that). Then we need to work out how to find that image of the comic. This new website agent will be fed by the previous agent, so the source section of the new website agent will need to be set to the name of the RSS reading agent that you've just created. We want to keep the information from that first Huginn agent, so set the mode to "merge". Then comes the fun part...
Let's get the json description for this agent out of the way, then go through what's happening:
{
"expected_update_period_in_days": "5",
"url": "{{url}}",
"type": "html",
"mode": "merge",
"extract": {
"comic": {
"css": "p.Maintext img",
"value": "substring-after(@src,\"../\")",
"array": "true"
}
}
}As you can see the input to this website agent is the {{url}} that was extracted in the previous agent's processing of the RSS feed's content. We're merging the data from that agent with the new variable ("comic") that is obtained from this agent - so that we can pass it all on the the output agent in the next step.
How do we extract the comic graphic from the web page that we extracted from the RSS - we need to know how to specify where it is... If you do a dry run of the previous website agent you'll get a set of variables for each RSS item, which contain the title & url for each entry. e.g.
{
"title": "JoT #2786: A Chip Crisis!",
"url": "https://www.geekculture.com/joyoftech/joyarchives/2786.html"
}Copy the url of one of them & open that web page in your browser. Then right click on the comic's image & choose inspect (or similar).
I'm using Firefox here:
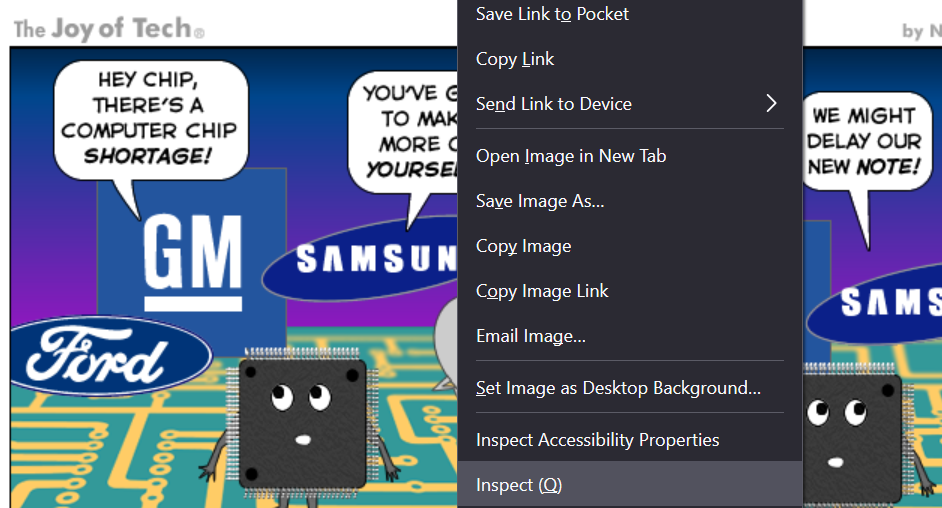
When you inspect, what you get is a window (frame) at the bottom of the page that shows you the html that's actually describing the page
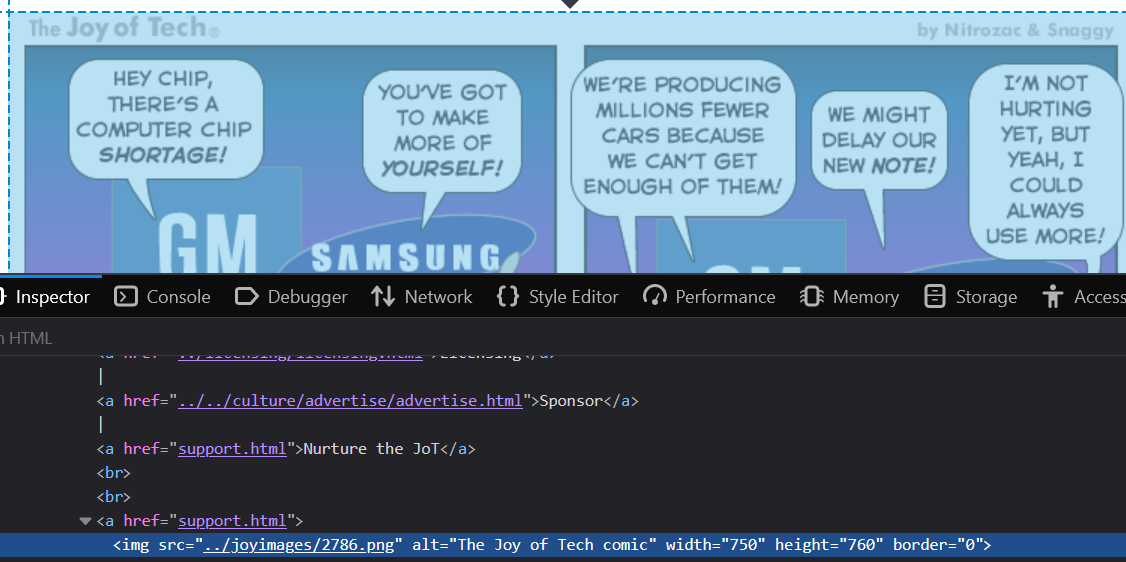
We can tell from that html that the image we want is at "../joyimages/2786.png", but we need to be able to pull that "src" from the web page of each of the RSS items as they are published. Which means that we need to describe where that can be found. Time for some disppointment, if you right click on that line with the img tag & choose "CSS selector" (a good way to find the specific location of a piece of web page that you are interested in ) then you'll get a css specification of "p.maintext img"... but it turns out that there are two maintext sections, both of which contain images... (you can eitther show this in the inspect window, or by doing a dry run of this agent with array=true once you find out that you get an error!)
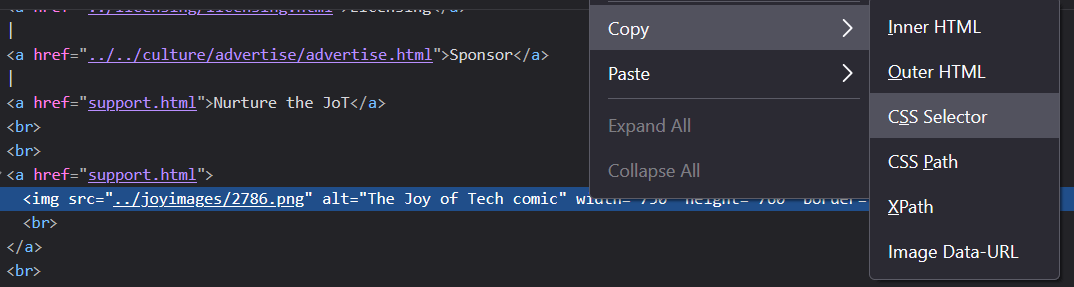
Which is a problem as Huginn can't pass a (single value) variable to the next step if there are several matches - which value should it choose?? We can get around that by answering "all of them" & then deal with choosing the right one in the next step. Which is why "array":"true" is there in the json - I'm saving all of the matches for an image in a maintext block, so that I can pick the right one later.
It's worth pointing out that we don't need the "../" part of the image location, we'll be adding the website domain part later on, so the selection specifies that we only collect the image location url after the "../" part.
We've now got an output of an array of images - from the page that was linked to - by the item - that was posted to the RSS feed (you might want to re-read that!). Along with the url & title that were in the RSS feed for that item at the very beginning (thanks to choosing to merge the agents' outputs).
Now we need to share the data as an RSS feed of our own...
Create a data output agent (new agent & pick data output agent). Tell it that it is being fed by the last website agent that we created by setting the source to that 2nd agent's name. Then it's a matter of creating our RSS feed so that it has the right data in the right places...
{
"secrets": [
"joy_of_tech"
],
"expected_receive_period_in_days": "5",
"template": {
"title": "Joy Of Tech Comic",
"description": "Joy Of Tech Comic",
"item": {
"title": "{{title}}",
"description": "<img src=\"https://www.geekculture.com/joyoftech/{{comic[0]}}\" alt={{title}}/>",
"link": "{{url}}"
}
},
"ns_media": "true"
}This json gives the whole feed a title & description, then creates an item (new post) for each output from the website scaper. It gives that item the same title as the original RSS feed used, & links to the original web page (that the RSS feed item was referencing). The description section is where we get the different experience - instead of a link to the web page & a thumbnail (which is what is in the original RSS) what we will get is the image that we located in the last website agent. The codeof that needs a little more explanation:
We know that all of the images are located at a basic path of https://www.geekculture.com/joyoftech/ (which is the the path of the web page in {{url}} (i.e. https://www.geekculture.com/joyoftech/joyarchives/ after following the ".." instruction (go one level higher)).
If you look at the output from the second (web page scraper) agent you can see that the image we want is the first item in the array (which is denoted as comic[0]) & that it has it's own location specified, relative to the basic path (in this example it's "joyimages/2786.png"). All we need to do is to join the basic path to the image's path & we'll be able to share it's location. In the json that's "https://www.geekculture.com/joyoftech/{{comic[0]}}". Add an alt text that's the same as the title & we're all done, apart from subscribing to Huginn's newly created RSS feed.
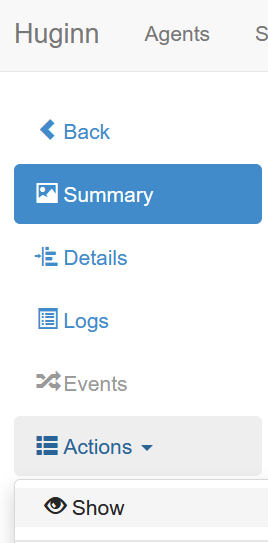
You can get the url for that by choosing "summary" from the output agent's page (click the "agents" menu, then the agent that you want, then the summary item on the left hand side if it's not already selected)
Put that URL in as a subscription in your favourite RSS reader & away you go!
Now all you need to do is find another RSS feed, duplicate the agents, change the json scripts to suit what you want for the new RSS feed & you have two RSS feeds.