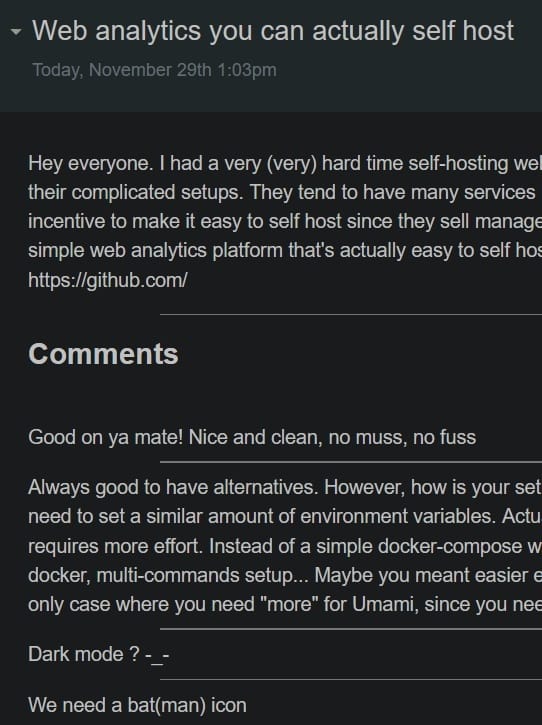
Redlib (via Huginn)
The redlib RSS feed reproduces the reddit equivalent, which gives you just the first post. If there's a real point to the communities on reddit it's that people answer these! It would be a lot easier if those answers were visible in the feed (given that you'd only have the answers up to the point that the RSS feed item was created). If the conversation looks interesting then you should be able to follow the link to the full thread in redlib.
Here is a possible scheme for doing that. I'm not going to claim that it's perfect (it ignores images for example).
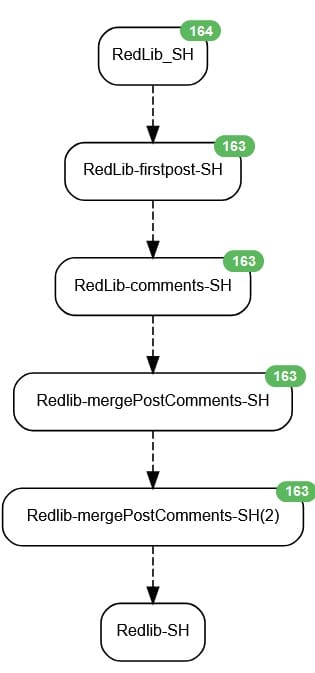
Read the RSS
Start with an rss agent & paste the url from the redlib rss into the "url" part of the configuration
{
"expected_update_period_in_days": "5",
"clean": "true",
"url": "http://192.168.1.2:8087/r/selfhosted.rss"
}Read the first post
Use a Website Agent.
I'm sure that I could do better, but this works to get the text of the original post. The redlib server is hard coded into the url_from_event.
After a bit of thinking & digging about I have a better solution to entering the server address into the agents. Go to the credentials page (via the menu at the top of Huginn's web page) & add a credential named redlib_server, with the protocol, ip address & port the you use ("http://192.168.1.2:8087" in my configs here). Then whenever you would use those in the agents replace that bit with{% credential redlib_server %}. i.e. for me"url_from_event": "http://192.168.1.2:8087{{becomes"url_from_event": "{% credential redlib_server %}{{
I've left the descriptions of the configs below unchanged, since they rely on an additional step that would be easy to miss.
The use of the description to get the link is because redlib sometimes ends up with the "link" pointing at a graphic, which is unhelpful for scraping the text of the original post!
For the value: To extract the innerHTML, use ./node(); and to extract the outer HTML, use .
{
"expected_update_period_in_days": "2",
"url_from_event": "http://192.168.1.2:8087{{ description | remove: '<a href=\"' | remove: '\">Comments<\/a>' }}",
"type": "html",
"mode": "merge",
"extract": {
"firstpost": {
"css": ".post_body > div:nth-child(1)",
"value": "string(.)"
}
}
}Now the comments
Pass that output to another website agent... The problem with the comments is that there are likely to be more than one of them. So a single match for the extraction is very unlikely. We will need to use an array to hold the individual comments, as they are found "single_array": "true".
{
"expected_update_period_in_days": "2",
"url_from_event": "http://192.168.1.2:8087{{ description | remove: '<a href=\"' | remove: '\">Comments<\/a>' }}",
"type": "html",
"mode": "merge",
"extract": {
"comments": {
"css": "div.comment_body",
"value": "string(.)",
"single_array": "true"
}
}
}Now we can merge things into a single message
(Event Formatting Agent).
We'll set "desc" to the link back to the redlib page, for use later. (You could use https://reddit.com instead of the redlib server (http://192.168.1.2:8087)if you think that you'd be more likely to want to log in & post a reply)
"comment" is a new field, made using a liquid template that loops through the "comments" array & adds each array item to the end of the comment field, followed by a <hr> (a horizontal line). The data used during this sort of processing only exists within those {}, so you have to use it or lose it.
The use of "word" as the token for each item is not important, it's just that I chose that instead of something like "item".
{
"instructions": {
"desc": "http://192.168.1.2:8087{{ description | remove: '<a href=\"' | remove: '\">Comments<\/a>' }}",
"comment": "{% for word in comments %}{{comment | append: word}}<hr>{% endfor %}"
},
"mode": "merge"
}A bit of tidying up
(Event Formatting Agent).
The "url" gets reliably & explicitly pointed at the redlib server place for the post.
We then update the "content" (couldn't do it from that {% %} loop - if you try you'll probably get the first post added to everything, despite being outside of the loop portion). The "content" starts with the original post, then a blank line, a horizontal line & then a title for the comments, followed by the aggregated comments that we created in the previous step. This whole long string then has some sanitisation of the escaped newline characters ("\\n") & the like.
The last little difference is that this time the mode is "clean", so any fields not mentioned are dropped from the message that's passed on to the next step (there were a lot of duplicates of the comments building up!)
{
"instructions": {
"id": "{{id}}",
"url": "{{desc}}",
"urls": [
"{{urls}}"
],
"links": [
"{{links}}"
],
"title": "{{title}}",
"description": "{{description}}",
"content": "{{firstpost | append: '<p><\/p><p><hr><\/p><H2>Comments<\/H2><br>' | append: comment | replace: '\\n' , '<p>' | replace: '\\\\n','<p>' | replace: '\\' , ' ' }}"
},
"mode": "clean"
}Another post hoc addition: I added a couple of links to the bottom of the post so that I can get to the "live" view of the comments (one for redlib & the other goes to Reddit to allow for logging in & commenting) . Replace the content entry above with the one just below here to get the same.
"content": "{{firstpost | append: '<p></p><p><hr></p><H2>Comments</H2><br>' | append: comment | replace: '\n' , '<p>' |replace: '\\n' , '<p>' | replace: '\\\\n','<p>' | replace: '\\' , ' ' | append: '<a href=\"https://reddit.com' | append: urls[0] | append: '\">Reddit</a>' | append: ' <a href=\"' | append: desc | append: '\">Redlib (Live)</a>' }}"Now we create our own RSS feed from the processed one
This is a data output agent. The "title" & "description" haven't been changed, but the "url" that the "link" items points to is the one that we created from the "desc" item earlier. Obviously the content entry is the one that we've worked hard to generate.
{
"secrets": [
"Self-Hosted"
],
"expected_receive_period_in_days": 2,
"template": {
"title": "Self-Hosted - with comments",
"description": "Reddit feed, generated by Huginn",
"item": {
"title": "{{title}}",
"description": "{{description}}",
"content": "{{content}}",
"link": "{{url}}"
}
},
"ns_media": "true"
}What's the result look like?